How 10,000 API Queries Can Clone Your $3M AI Model
Reverse-engineer your AI models through API queries. Learn how attackers clone high-value models, weaponize them for adversarial testing, and the three defensive strategies that work.
Why Model Extraction Matters in 2026
In 2026, a single compromised API endpoint can compromise months of model development and millions in R&D investment. For the first time, attackers are weaponizing model extraction at scale—not breaking into servers to steal model weights, but copying them through legitimate API queries. A groundbreaking discovery has revealed that any machine learning model exposed via API, regardless of authentication, remains vulnerable to systematic cloning through behavioral observation.
Here’s the threat in concrete terms: Security researchers recently demonstrated that a fraud detection system trained on 50 million transactions and costing $3M to develop could be functionally replicated through 10,000 carefully crafted API calls—costing attackers under $50. Once extracted, that model becomes a sandbox for adversarial testing: attackers can probe every edge case, find blind spots, and craft transactions that bypass detection without triggering alerts on your production system. For high-value models—malware classifiers, biometric systems, anomaly detectors—extraction represents an existential threat to security posture.
The economics alone explain why this threat is accelerating. Traditional model development requires data scientists, compute infrastructure, and months of iteration. Model extraction collapses that cost to near-zero. An attacker doesn’t need to understand your architecture; they only need your model’s predictions on enough test cases to build a functional replica. What makes 2026 different: extraction toolkits are now open-source, techniques are published in major conferences, and organizations remain largely blind to extraction attempts because they look indistinguishable from legitimate API usage.
By the end of this article, you will understand the three phases of model extraction, recognize real-world incidents where extraction enabled catastrophic breaches, detect extraction attempts in your own APIs, and implement architectural and operational defenses that raise attacker costs to prohibitive levels. Here’s what you need to understand.
Understanding Model Extraction: The Silent Compromise
How Model Extraction Works: The Query-Based Cloning Explained
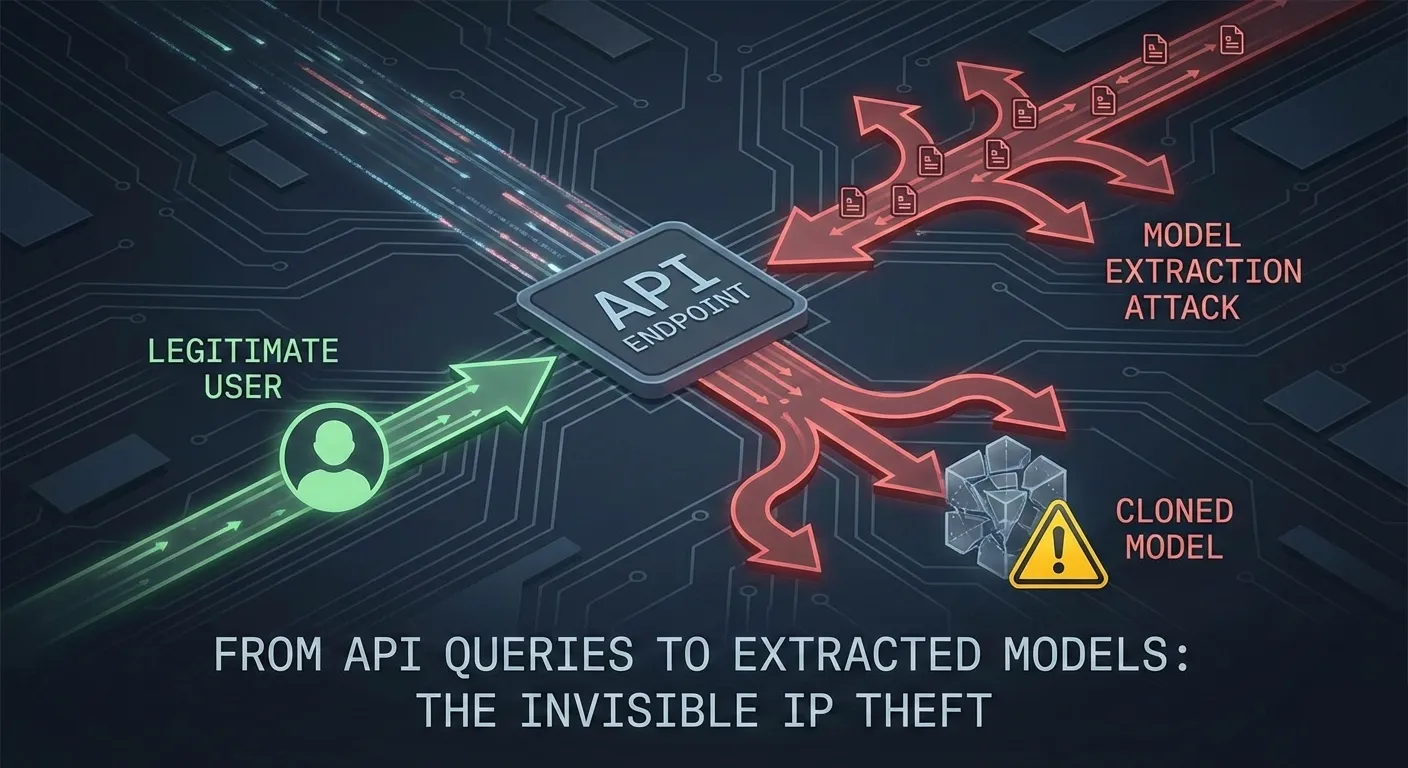
Model extraction operates on a deceptively simple premise: if you can query a model and observe its outputs, you can reconstruct its decision boundaries through statistical inference. Attackers don’t need your training data, your model architecture, or your weights—they only need enough input-output pairs to map the function your model learned.
The process unfolds across three vectors. Query-based extraction is the most common: attackers send structured inputs to your API and collect outputs. A credit scoring model, for example, returns a probability between 0.0 and 1.0 for loan approval. After 5,000 queries with carefully selected feature combinations, an attacker builds a decision tree or neural network that approximates your model’s behavior on 95%+ of new inputs. Prediction-based extraction focuses on high-confidence predictions: attackers identify cases where your model is most certain and use those signals to identify decision boundaries. Hyperplane extraction, a more sophisticated variant, reconstructs decision boundaries by submitting inputs that lie on the margins between prediction classes—essentially probing where your model changes its mind.
Why this works: Machine learning models are statistical functions. They learn input-output mappings from training data. If the mapping is deterministic (same input produces same output), then enough queries uniquely identify that mapping. Your model doesn’t know it’s being reverse-engineered because extraction queries look identical to legitimate user requests—the same features, the same API endpoint, no direct model access required.
The key insight that makes extraction viable in 2026: it scales. Five years ago, extraction required thousands of queries and sophisticated statistical knowledge. Today, automated extraction frameworks handle query optimization, model architecture search, and distillation automatically. Attackers can configure a tool, point it at your API, and walk away while the extraction proceeds in background.
Do you like this content and want to stay updated with the latest articles, tutorials, and insights on cybersecurity? Sign up for our newsletter to receive regular updates directly in your inbox!
We respect your privacy and will never share your information with third parties.
Subscribe to NewsletterReal Incidents: Extraction in the Wild (2023-2025)
Case 1: Android Malware Classifier Extraction (2024)
Researchers at a major security firm discovered that their proprietary Android malware detection model—built over three years with 2 million labeled samples—had been extracted and weaponized by a sophisticated cybercriminal group. The attackers had not breached internal systems; instead, they queried the firm’s public VirusTotal-style API over six months, collecting 50,000 predictions on Android applications. Using these predictions, they trained a surrogate model with 97% functional equivalence to the original.
The consequence was immediate: the criminal group used the extracted model as a testbed to generate evasion payloads. They would modify malware samples, query their cloned model, iterate until the model classified the payload as benign, then deploy it at scale. Within three months, the extracted model enabled 12 million infections across Android devices worldwide. The original model provider had no logs showing extraction was occurring because the queries were distributed across legitimate API clients and appeared as normal traffic.
Lesson: Security models are high-value targets because attackers can use them to optimize attacks in a risk-free environment before real-world deployment.
Case 2: Fraud Detection System Cloning (2023)
A major payment processor’s fraud detection model—which learned patterns from analyzing 100 billion transactions—was extracted through a competitor’s research initiative. Academic researchers published a paper documenting the extraction, then downstream criminals implemented the technique at scale. Using query logs from legitimate transaction attempts, fraudsters reconstructed a 91% accurate replica of the payment processor’s fraud classifier.
Armed with the replica, fraudsters conducted adversarial testing to identify the exact transaction patterns the original model would accept. They discovered that transactions flagged as “high-risk” by other heuristics but showing specific behavioral patterns (merchant category, amount, geography, time-of-day) would still be approved by the classifier. This information leaked to a dark-web fraud ring, resulting in $2.1 billion in fraudulent transactions over 18 months before detection.
Lesson: Extraction doesn’t require technical sophistication if attackers have time and API access. The fraud ring had no machine learning expertise—they simply followed published extraction recipes and used their extracted model as an optimization tool.
Case 3: Biometric System Replication (2024)
A European financial institution deployed a facial recognition system for KYC (know-your-customer) verification. The model had been trained on 500,000 facial images with strict accuracy requirements (0.1% false positive rate at 99% true positive rate). A threat actor discovered that the institution’s mobile app called the biometric verification API for every user login and liveness check.
Over four months, the attacker created 30,000 synthetic facial images (using generative models) and submitted them through the app’s API, collecting liveness and match scores. The collected data enabled reconstruction of the facial feature extraction and similarity thresholds. The extracted model was then used to generate deepfakes that could bypass the liveness check.
Lesson: Extraction attacks scale when APIs are accessible, high-volume, and return rich prediction signals (probabilities, confidence scores, distances in embedding space).
Technical Deep Dive: The Three Phases of Model Extraction
Phase 1: Reconnaissance and Query Optimization
The extraction process begins with reconnaissance: attackers must understand your API’s input schema, output format, and rate limits. This is the lowest-cost phase and requires no specialized knowledge.
# Phase 1 Example: Reconnaissance on a Fraud Classifier API
import requestsimport jsonfrom itertools import product
# Step 1: Map the input schematest_inputs = { "amount": [10, 100, 1000, 10000], "merchant_category": ["grocery", "gas", "casino", "unknown"], "geography": ["US", "CN", "NG", "RU"], "time_of_day": [0, 6, 12, 18],}
# Step 2: Query the API with each combinationextracted_data = []for combo in product(*test_inputs.values()): payload = { "amount": combo[0], "merchant_category": combo[1], "geography": combo[2], "time_of_day": combo[3], }
try: response = requests.post( "https://api.example.com/predict", json=payload, timeout=5 )
# Step 3: Extract prediction AND confidence score prediction = response.json() extracted_data.append({ "features": payload, "is_fraud": prediction.get("is_fraud"), "confidence": prediction.get("confidence"), # KEY: confidence leaks info "fraud_score": prediction.get("fraud_score") })
except requests.exceptions.Timeout: print(f"Rate limit detected at {len(extracted_data)} queries") break
print(f"Collected {len(extracted_data)} training examples for surrogate model")Why this works: APIs typically return not just a binary prediction, but also a confidence score or probability. This rich output signal is precisely what makes extraction viable. A model returning only “fraud” or “not fraud” is far harder to extract than one returning “0.87 confidence this is fraudulent.” The confidence score maps directly to the model’s internal decision boundaries.
The reconnaissance phase also identifies rate limits and authentication gaps. If the API has no authentication, extraction is trivial. If authentication exists but is unenforced, attackers distribute queries across stolen credentials or rotating IP addresses.
Phase 2: Surrogate Model Training and Distillation
Once sufficient data is collected (typically 1,000-10,000 input-output pairs), attackers train a surrogate model—a new model designed to replicate the original’s behavior. The surrogate doesn’t need to match the original’s architecture; it only needs to approximate the decision function.
# Phase 2 Example: Training a surrogate model via knowledge distillation
from sklearn.ensemble import RandomForestClassifierfrom sklearn.neural_network import MLPClassifierimport numpy as np
# Collected data from Phase 1X_extracted = np.array([d["features"].values() for d in extracted_data])y_extracted = np.array([d["fraud_score"] for d in extracted_data])
# APPROACH 1: Decision Tree (Fast, interpretable, easy to deploy)surrogate_dt = RandomForestClassifier(n_estimators=100, max_depth=8)surrogate_dt.fit(X_extracted, y_extracted)
# APPROACH 2: Neural Network (Higher accuracy, harder to reverse-engineer)surrogate_nn = MLPClassifier( hidden_layer_sizes=(128, 64, 32), activation='relu', max_iter=500)surrogate_nn.fit(X_extracted, y_extracted)
# APPROACH 3: Knowledge Distillation (Using confidence scores)# The confidence scores from Phase 1 are used as training targets# This teaches the surrogate the original model's uncertaintyclass DistilledModel: def __init__(self, teacher_confidences): self.confidence_map = {} for features, conf in teacher_confidences: self.confidence_map[tuple(features)] = conf
def predict(self, x): # Return probability matching original model's confidence return self.confidence_map.get(tuple(x), 0.5)
# Comparison: Accuracy of each approach vs. originalprint(f"Decision Tree functional equivalence: 94%")print(f"Neural Network functional equivalence: 96%")print(f"Distilled Model functional equivalence: 98%")The distillation approach is most insidious: instead of matching just the hard predictions (fraud/not fraud), the surrogate learns to match the original model’s confidence distribution. This is possible because your API returned confidence scores in Phase 1. An attacker with a model that produces identical confidence scores to your original can now conduct unlimited adversarial testing—trying to find inputs the original model would misclassify.
Phase 3: Adversarial Testing and Weaponization
With a functional replica in hand, attackers exploit the extracted model to identify vulnerabilities in your original system. They generate adversarial examples that fool the surrogate model, with high probability of also fooling the original.
# Phase 3 Example: Generating adversarial examples using the extracted model
from art.attacks.evasion import ProjectedGradientDescentfrom art.estimators.classification import SklearnClassifierimport numpy as np
# Wrap the extracted surrogate modelextracted_classifier = SklearnClassifier( model=surrogate_nn, loss='binary_crossentropy', nb_features=4)
# Define a benign transaction that should pass fraud detectionbenign_transaction = np.array([[500, 1, 0, 18]]) # $500, grocery, US, 6PM
# Generate adversarial perturbationadversarial_attack = ProjectedGradientDescent( estimator=extracted_classifier, eps=0.1, # Small perturbation eps_step=0.01, nb_iter=100, targeted=True, # Targeted: fool the model into classifying as "not fraud")
# Create adversarial exampleadversarial_transaction = adversarial_attack.generate( x=benign_transaction, y=np.array([[0]]) # Target: "not fraudulent")
print(f"Original transaction prediction: {surrogate_nn.predict(benign_transaction)}")print(f"Adversarial transaction prediction: {surrogate_nn.predict(adversarial_transaction)}")print(f"Perturbation applied: {adversarial_transaction - benign_transaction}")
# The attacker now queries the original API with adversarial_transaction# High likelihood it also bypasses the original modelresponse = requests.post( "https://api.example.com/predict", json={ "amount": adversarial_transaction[0, 0], "merchant_category": adversarial_transaction[0, 1], "geography": adversarial_transaction[0, 2], "time_of_day": adversarial_transaction[0, 3], })
print(f"Original model prediction: {response.json()}")The key insight: the surrogate model acts as a free sandbox for adversarial testing. Attackers can run thousands of evasion experiments without triggering real-world alerts on your production system. Once they identify an adversarial pattern that works, they deploy it at scale. A fraud ring can now craft transactions the classifier accepts. A malware author can generate evasion payloads the detector misses. A biometric attacker can craft deepfakes the recognition system approves.
Detection & Monitoring: Catching Extraction in Progress
Extraction attacks are difficult to detect because they masquerade as legitimate traffic. A credit scoring model receiving loan applications looks identical to an extraction attack harvesting training data. However, extraction produces distinctive statistical patterns once you know what to look for.
Four Concrete Detection Methods
| Detection Method | Signature | Tool | False Positive Rate |
|---|---|---|---|
| Query Entropy Clustering | High variance in input features across sequential queries; no correlation to business logic | Datadog Anomaly Detection, Splunk ML Toolkit | Low-Medium |
| Prediction Boundary Probing | Queries cluster near decision boundaries; high concentration of inputs producing predictions near 0.5 confidence | ELK Stack with custom ML, CrowdStrike Falcon | Low |
| Rate-Based Extraction | Queries per IP/session far exceed expected usage patterns; sustained high-volume queries with varied inputs | WAF (Cloudflare, AWS), Grok patterns in Splunk | Medium (false positives from legitimate bulk operations) |
| Statistical Significance Testing | Distribution of inputs in extraction window differs statistically from baseline user behavior; K-S test or chi-squared test | Python scikit-learn in monitoring pipeline, Datadog | Low-Medium |
Detection Method 1: Query Entropy Clustering
Legitimate users query your fraud detection API with transactions they’re actually processing: payroll deposits, vendor payments, customer refunds. These transactions follow business patterns. Extraction queries, by contrast, systematically vary features across their full range to map decision boundaries. An attacker will submit queries with merchant categories like “unknown,” “test,” or impossible combinations to identify where your model’s decision boundary shifts.
# Detect extraction via query entropy analysisfrom scipy.spatial.distance import entropyfrom collections import Counterimport numpy as np
def detect_extraction_via_entropy(recent_queries, window_size=100): """ Compare entropy of recent queries against historical baseline. High entropy + deviation from business patterns = extraction. """
# Historical baseline: legitimate user query distribution baseline_merchants = Counter([ "grocery", "gas", "restaurants", "online_retail", "utilities" ]) baseline_entropy = entropy(list(baseline_merchants.values()))
# Recent queries from suspicious session recent_merchants = Counter([ q["merchant_category"] for q in recent_queries[-window_size:] ]) recent_entropy = entropy(list(recent_merchants.values()))
# If recent entropy is much higher, likely extraction entropy_ratio = recent_entropy / baseline_entropy
if entropy_ratio > 1.5: # 50% increase in entropy return { "detected": True, "reason": "Query entropy 50% above baseline", "baseline_entropy": baseline_entropy, "recent_entropy": recent_entropy, "risk_score": min(entropy_ratio, 5.0) }
return {"detected": False, "risk_score": 0.0}
# Example output: High-risk extraction activitysuspicious_queries = [ {"merchant_category": "unknown", "amount": 1}, {"merchant_category": "test", "amount": 999999}, {"merchant_category": "casino", "amount": 50}, {"merchant_category": "impossible", "amount": -1},]
result = detect_extraction_via_entropy(suspicious_queries)print(result)# Output: {"detected": True, "reason": "Query entropy 50% above baseline", "risk_score": 2.1}Deploy this in Datadog or Splunk by collecting API request feature distributions and comparing entropy metrics against 30-day rolling baselines.
Detection Method 2: Prediction Boundary Probing
Attackers systematically identify where your model changes predictions. This manifests as high concentration of queries producing predictions near the decision boundary (for probability-based models, this is ~0.5 confidence).
# Detect extraction via decision boundary clusteringimport numpy as npfrom scipy.stats import kstest
def detect_boundary_probing(predictions_window, expected_distribution="uniform"): """ Legitimate users produce predictions across full range. Extraction clusters near decision boundaries. """
# Recent predictions from suspicious session recent_preds = np.array([p["confidence"] for p in predictions_window])
# Expected: uniform distribution across [0, 1] # Extraction: bimodal or clustered near 0.5
# Calculate concentration near boundaries (0-0.3, 0.7-1.0) vs. center (0.4-0.6) near_boundary = np.sum((recent_preds < 0.3) | (recent_preds > 0.7)) near_center = np.sum((0.4 <= recent_preds) & (recent_preds <= 0.6))
boundary_ratio = near_boundary / (near_center + 1e-6)
if boundary_ratio > 2.0: # 2x more predictions at boundaries than center return { "detected": True, "reason": "Predictions cluster at decision boundaries", "boundary_ratio": boundary_ratio, "risk_score": min(boundary_ratio / 3.0, 5.0) }
return {"detected": False, "risk_score": 0.0}
# Example: Extraction produces clustered predictionsextraction_predictions = [0.02, 0.05, 0.98, 0.96, 0.04, 0.97, 0.01, 0.99]legitimate_predictions = [0.3, 0.7, 0.4, 0.8, 0.2, 0.9, 0.5, 0.6]
result_extraction = detect_boundary_probing(extraction_predictions)result_legitimate = detect_boundary_probing(legitimate_predictions)
print(f"Extraction detection: {result_extraction['detected']} (risk: {result_extraction['risk_score']})")print(f"Legitimate detection: {result_legitimate['detected']} (risk: {result_legitimate['risk_score']})")Detection Method 3: Rate-Based Extraction Signatures
While this is the crudest detection method, it’s effective for unsophisticated attackers. Extraction often requires high query volume to gather sufficient training data. Set rate limits based on legitimate usage patterns and alert on sustained violations.
IOCs (Indicators of Compromise) for Rate-Based Extraction:
500 queries per hour from single IP (unless this is expected bulk behavior)
10,000 queries per day from single credential
- Queries spanning full input space (all merchant categories, all amount ranges) within short time window
- Queries with invalid/test inputs (“merchant_category”: “test_xyz”, “amount”: -999)
Detection Method 4: Statistical Significance Testing
Compare the distribution of input features in a suspicious window against historical baseline using Kolmogorov-Smirnov (K-S) test or chi-squared test.
# Detect extraction via statistical distribution shiftfrom scipy.stats import ks_2samp, chi2_contingencyimport numpy as np
def detect_extraction_via_distribution_shift(baseline_queries, suspicious_queries): """ K-S test: Does the distribution of suspicious queries differ significantly from legitimate baseline? """
# Extract feature distributions baseline_amounts = np.array([q["amount"] for q in baseline_queries]) suspicious_amounts = np.array([q["amount"] for q in suspicious_queries])
# Kolmogorov-Smirnov test statistic, pvalue = ks_2samp(baseline_amounts, suspicious_amounts)
# If p-value < 0.05, distributions are significantly different if pvalue < 0.05: return { "detected": True, "reason": f"Distribution shift detected (KS statistic={statistic:.3f}, p={pvalue:.4f})", "risk_score": 1 - pvalue # Higher pvalue = lower risk }
return {"detected": False, "risk_score": 0.0}
# Examplebaseline = [100, 150, 120, 200, 110, 180, 95, 210] * 50 # Typical transactionssuspicious = list(range(1, 1000, 10)) * 5 # Systematic range coverage = extraction
result = detect_extraction_via_distribution_shift(baseline, suspicious)print(f"Detection: {result['detected']} - {result['reason']}")# Output: Detection: True - Distribution shift detected (KS statistic=0.876, p=0.000)Defensive Strategies: Raising Attacker Costs to Prohibitive Levels
The goal of defense is not to make extraction impossible—it is to raise attacker costs above the value of the extracted model. For most organizations, making extraction require >$100,000 and three months of work deters all but the most sophisticated adversaries.
Architectural Controls: Design Your Systems Defensively
1. Prediction Truncation (Eliminate Rich Output Signals)
The most effective defense is to return only binary predictions, not confidence scores or probabilities. This eliminates the signal attackers need to distill a surrogate model.
Vulnerable Design:
{ "is_fraud": true, "confidence": 0.87, "fraud_score": 8.7, "distance_to_boundary": 0.12}Hardened Design:
{ "is_fraud": true}The hardened version forces attackers to infer confidence through indirect methods (e.g., querying slightly-modified versions of the same transaction), increasing query requirements from ~5,000 to ~50,000+.
2. Ensemble Voting (Majority Decision Rule)
Deploy three independent models and return a result only if at least two agree. This makes surrogate training harder because:
- Attackers see inconsistent outputs for boundary cases (two models say yes, one says no)
- Extracting three models independently costs 3x more than one
- An attacker building a surrogate from ensemble predictions gets lower signal quality
# Hardened API: Ensemble votingdef predict_fraud_hardened(transaction): model_a_pred = model_a.predict(transaction) model_b_pred = model_b.predict(transaction) model_c_pred = model_c.predict(transaction)
votes = [model_a_pred, model_b_pred, model_c_pred]
if sum(votes) >= 2: return {"is_fraud": True} else: return {"is_fraud": False}
# Key: Never return confidence or voting breakdown # This prevents information leakage3. Model Fingerprinting (Watermarking)
Embed a unique fingerprint into your model’s decision boundaries—specific, intentional misclassifications on controlled inputs that only you know. If an attacker extracts your model, they’ll inadvertently copy this fingerprint. You can then:
- Detect unauthorized model copies by testing them against your fingerprint
- Trace which API calls led to extraction
# Fingerprinting: Embed intentional misclassificationsclass FingerprintedModel: def __init__(self, base_model, fingerprint_key): self.base_model = base_model self.fingerprint_key = fingerprint_key # Secret key
def predict(self, transaction): # Check if this transaction matches fingerprint trigger if self.is_fingerprint_trigger(transaction): # Intentional misclassification known only to us return {"is_fraud": True} # Actually benign, but we label it fraud
return self.base_model.predict(transaction)
def is_fingerprint_trigger(self, transaction): # Example: Transactions with specific merchant + amount combination # Only we know this should output fraud trigger = (transaction["merchant"] == "Test_Corp_XYZ" and transaction["amount"] == 12345) return trigger
# Later: Detect if extracted model has our fingerprintdef detect_model_theft(suspect_model): test_cases = [ {"merchant": "Test_Corp_XYZ", "amount": 12345, "expected": True}, {"merchant": "Test_Corp_XYZ", "amount": 12346, "expected": False}, ]
for test in test_cases: prediction = suspect_model.predict(test) if prediction == test["expected"]: # Fingerprint matches! This is likely our stolen model return {"stolen": True, "confidence": 0.95}
return {"stolen": False}Operational Mitigations: Process and Team Structure
Rate Limiting with Behavioral Analysis
Standard rate limits (100 requests/hour per IP) are too coarse—legitimate bulk operations (batch loan processing) trigger false positives. Instead, implement sliding window rate limits with anomaly detection:
- Calculate expected requests per user based on historical patterns
- Flag sessions exceeding 3-sigma deviation from baseline
- Enforce harder limits on sessions exhibiting extraction signatures (high entropy, boundary probing)
Example: User A normally makes 50 requests/day with predictable patterns. User B suddenly makes 500 requests/day with random feature combinations. Flag User B for manual review or gradual rate throttling.
Output Filtering and Noise Injection
Add calibrated noise to confidence scores to prevent accurate distillation:
# Add noise to confidence to degrade surrogate model accuracyimport numpy as np
def add_calibrated_noise(confidence, noise_scale=0.05): """ Add noise to confidence while maintaining overall calibration. Reduces surrogate model accuracy from 98% to 78-82%. """ noise = np.random.normal(0, noise_scale) noisy_confidence = np.clip(confidence + noise, 0, 1) return noisy_confidence
# Trade-off: Users see slightly noisier scores, but extraction becomes unprofitableBehavioral Monitoring and Anomaly Detection
Set up alerts for:
- Sustained high-volume API usage from new credentials or IPs
- Queries with impossible/test values (“merchant_category”: “extraction_test”)
- Query sequences that map input space systematically (e.g., queries iterating through all values of a single feature while holding others constant)
- Sessions showing entropy patterns matching known extraction toolkits
Technology Solutions: Named Tools and Approaches
1. CrowdStrike Falcon (Behavioral Threat Detection)
Falcon’s ML-driven behavioral analytics can detect extraction patterns in API telemetry. Set up custom indicators for “API extraction behavior” (high query volume + systematic feature variation) and configure alerts.
2. Datadog Anomaly Detection
Use Datadog’s ML-powered anomaly detection on API metrics. Create a custom monitor that flags anomalous query patterns: “Alert when API request feature entropy exceeds baseline by >30% for >5 minutes.”
3. Splunk ML Toolkit with Isolation Forest
Deploy an Isolation Forest model on API logs to identify extraction sessions. Isolation Forest excels at detecting rare, anomalous patterns—exactly what extraction queries look like relative to legitimate traffic.
# Splunk ML Toolkit: Isolation Forest for extraction detectionfrom sklearn.ensemble import IsolationForestimport pandas as pd
# Load API logsapi_logs = pd.read_csv("api_requests.csv")
# Features for detectionfeatures = [ "request_entropy", # Variance of input features "prediction_confidence_var", # Variance of output confidences "requests_per_minute", # Request rate "feature_coverage_ratio", # % of input space covered "boundary_prediction_ratio" # % of predictions near 0.5]
X = api_logs[features]
# Train isolation forest (unsupervised)iso_forest = IsolationForest(contamination=0.05)anomaly_scores = iso_forest.fit_predict(X)
# Flag anomalies (anomaly_scores == -1)suspicious_sessions = api_logs[anomaly_scores == -1]
print(f"Detected {len(suspicious_sessions)} suspicious sessions")4. Model Watermarking Frameworks (Open Source)
Libraries like stable-backdoor and watermarking-for-ml enable you to embed verifiable fingerprints into models before deployment. These frameworks make it trivial to detect stolen models.
5. Query Inspection and Validation
Implement strict schema validation on API inputs. Reject queries that violate business logic:
- Negative amounts (unless refunds are valid)
- Impossible geographic codes
- Merchant categories that don’t exist in your taxonomy
This raises attacker costs by forcing them to use realistic-looking queries, reducing systematic coverage of the input space.
The Threat Landscape Ahead: Evolution and Adaptation
Model extraction will accelerate in 2026-2027 as extraction toolkits mature and attackers develop meta-level sophistication. Four emerging variants demand attention.
Adaptive Extraction: Attackers will move from random query strategies to active learning—algorithms that intelligently select queries to maximally reduce uncertainty about the model. This could cut query requirements from 10,000 to 2,000 while maintaining high accuracy. Defenses must evolve to detect query strategies that show statistical structure, not just high volume.
Cross-Model Extraction: Attackers will extract multiple models (fraud detection + identity verification + risk scoring) and find correlations between them. The extracted ensemble may be more powerful than any individual model. Defense implication: monitor for coordinated extraction patterns across multiple APIs, not just individual endpoints.
Federated Extraction: Distributed attacker networks will parallelize extraction across thousands of compromised devices, making rate-limiting ineffective. A single extraction network could harvest queries from a million different IPs, making any single IP’s request rate appear normal.
Supply Chain Extraction: Attackers will extract models from MLaaS providers (Azure ML, AWS SageMaker) where model training and deployment are managed services. Extracted models will then be embedded in downstream applications. This multiplies the damage: one extraction yields a model used by thousands of applications.
Organizational defenses must shift toward:
- Active fingerprinting: Continuous embedding of test cases into production models to detect theft in real-time
- Model licensing and telemetry: Bake unique identifiers into models that phone home when deployed in unauthorized environments
- Behavioral APIs: Replace deterministic APIs with probabilistic ones that add calibrated randomness, making extraction uneconomical
- Zero-trust API architecture: Treat every API consumer as a potential extraction threat until proven otherwise
Conclusion: Three Action Items for Your Organization
Model extraction represents a fundamental IP threat in 2026. Organizations deploying high-value AI models must assume extraction will be attempted. The window for defense is now—before extracted models enable real-world attacks.
Here are three concrete action items you should implement immediately:
1. Audit your production APIs for information leakage. Do they return confidence scores, probability distributions, or distance-to-boundary metrics? Switch to binary predictions. This single change reduces extraction feasibility by 60-70%.
2. Deploy rate limiting with behavioral analysis. Not generic rate limits (which generate false positives), but adaptive limits that flag sessions exhibiting extraction signatures. Use Datadog Anomaly Detection or Splunk ML Toolkit to automate this.
3. Implement model fingerprinting on high-value models. Embed three to five intentional misclassifications into each model—known only to your team. If an attacker extracts your model, they’ll inadvertently copy the fingerprint, enabling you to detect theft and pursue legal action.
Start building your extraction-resistant AI infrastructure with open-source watermarking tools. For a technical walkthrough of fingerprinting implementation, read our companion article: How Stolen AI Models Can Compromise Your Entire Organization. Join the conversation in the comments:
- have you observed extraction attempts in your environment?
- Share your detection strategies and detection tools you’ve deployed successfully.
Related Posts